[1] 데이터 전처리
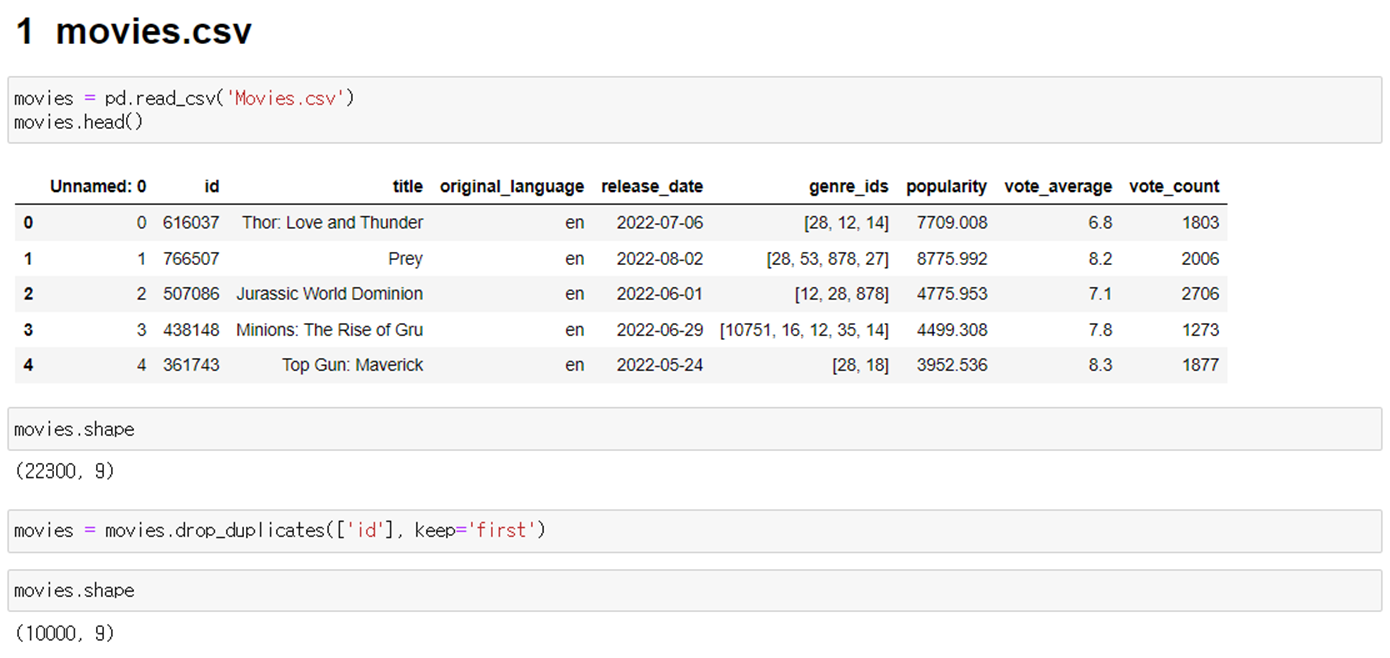
1. Kaggle 사이트의 Movies.csv 사용
- 중복 제거 전(행, 열) : (22,300, 9) -> 중복 제거 후 : (10,000, 9)
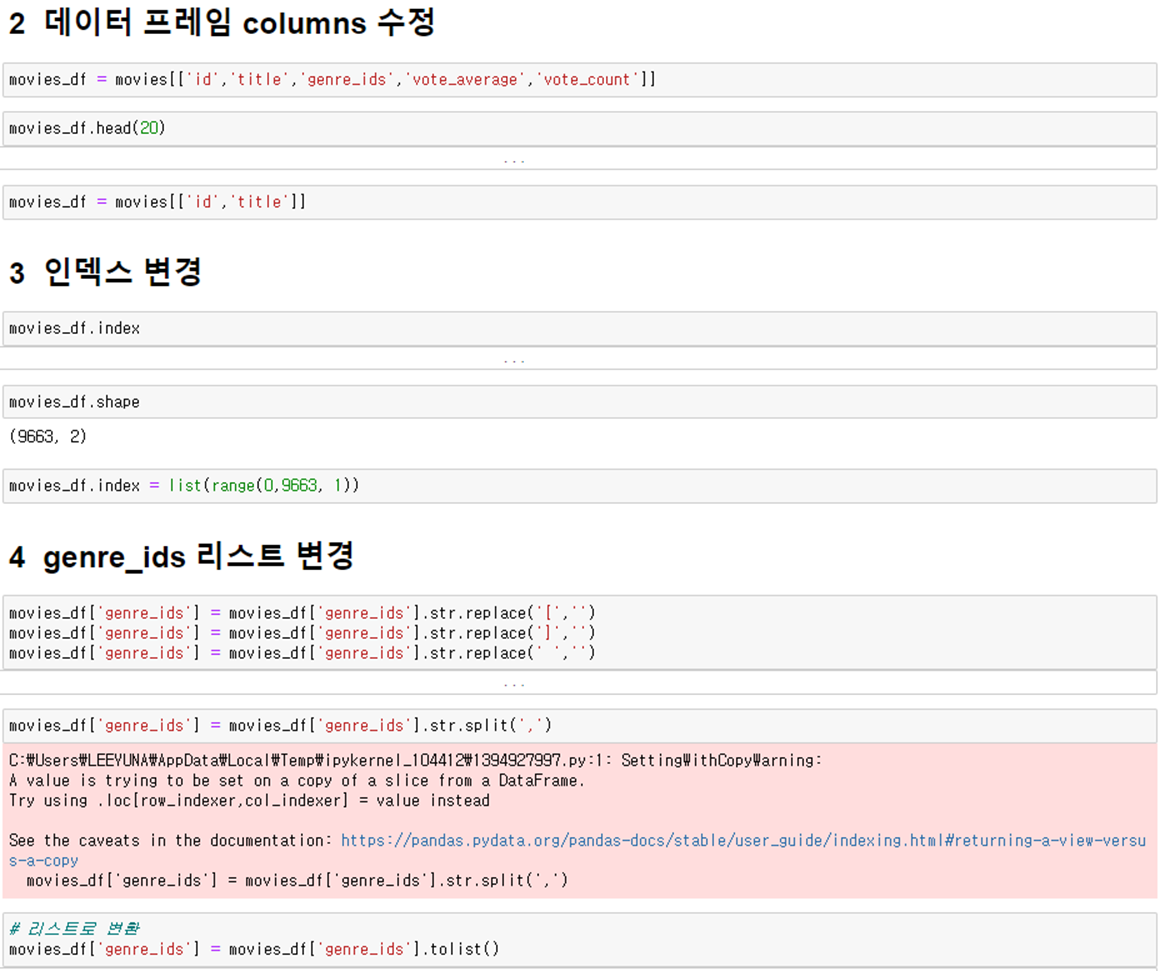
2. 전처리 데이터 pre_movies.csv 저장
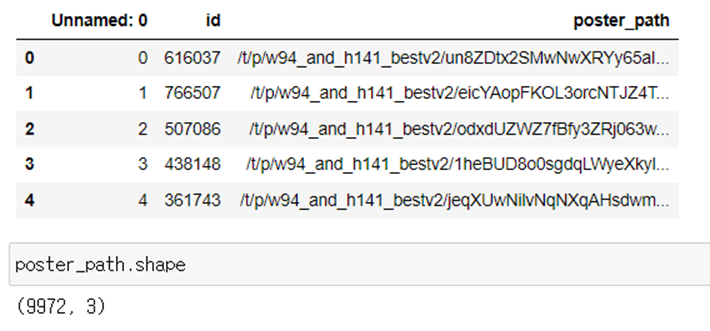
3. poster_path 크롤링 (TMDB 사이트)

- 결과 값 일부 (크롤링 데이터 : poster_df.csv 저장)
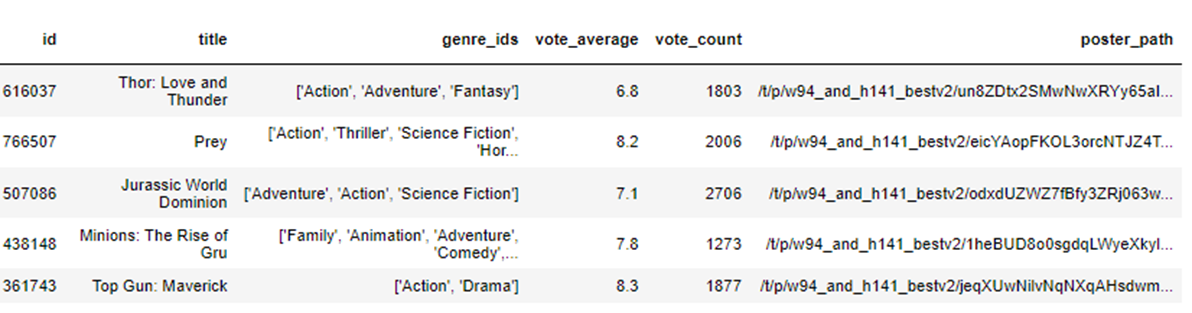
4. pre_movies.csv + poster_df.csv merge, end_movies.csv 저장 (장고에서 read.csv 하기 위한 과정)
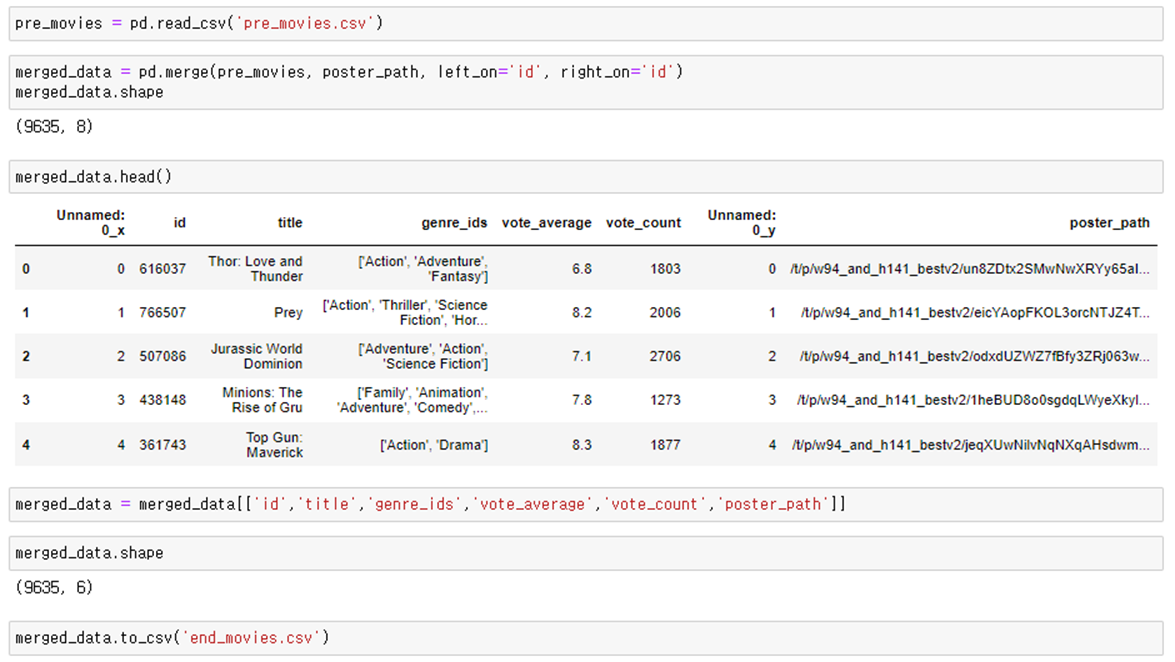
- end_movies.csv 일부
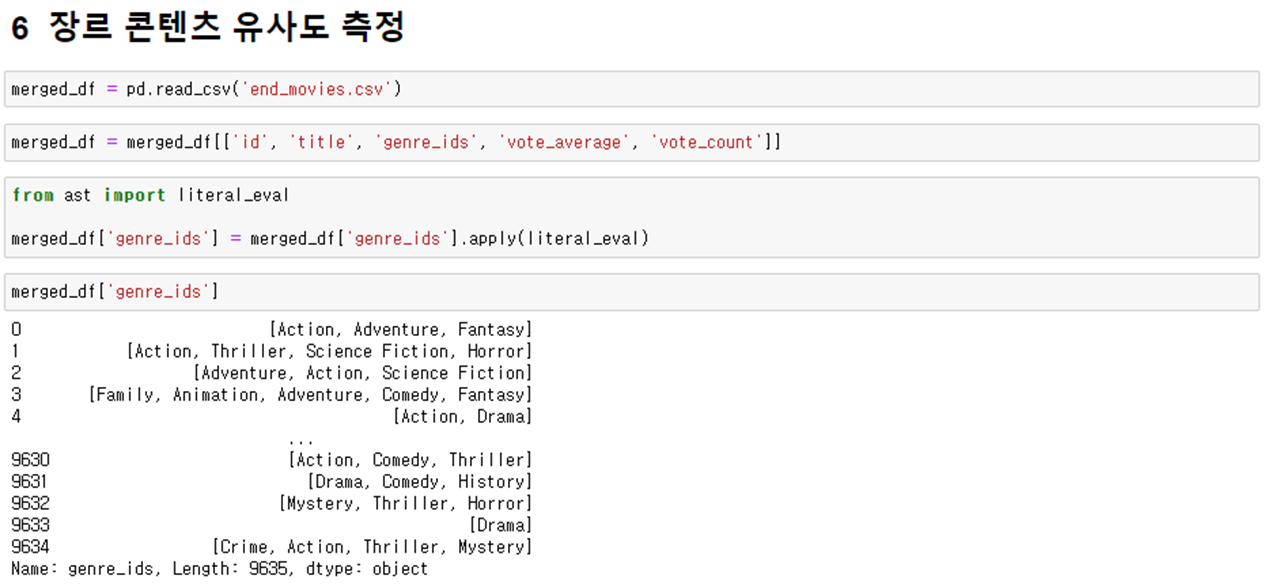
5. 장르 콘텐츠 유사도 측정
5-1) literal_eval : ‘genre_ids’ 문자열을 리스트 형태로 변환
5-2) CounterVectorizer : ‘genre_id’ count하여, 장르 빈도수 행렬 생성

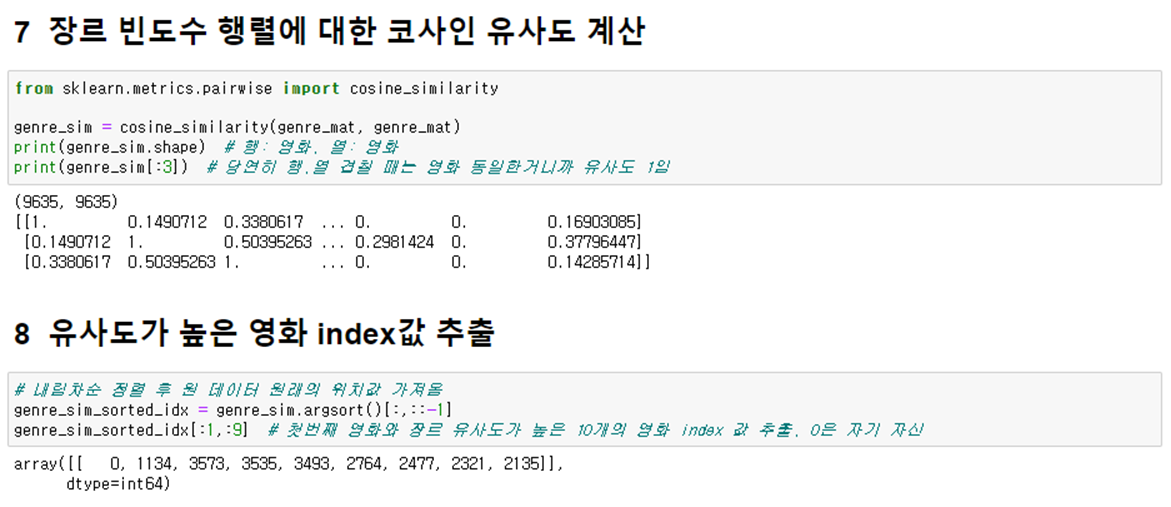
6. 장르 빈도수 행렬에 대한 코사인 유사도 계산
- Cosine Similarity : -1, 1 사이의 값을 가지며 값이 1에 가까울수록 유사도가 높음
7. 가중 평점 도입
- weighted_vote(가중평점 도입) : 평균 vote_count, vote_average 사용한 가중 평균 사용

'프로젝트 > 콘텐츠 추천 프로젝트' 카테고리의 다른 글
| [머신러닝, Jupyter NoteBook] 장르/줄거리/감독/배우 기반 필터링 전처리 (1) | 2023.03.15 |
|---|---|
| [머신러닝, Django] 장르 기반 필터링 구현 (0) | 2023.03.15 |
| [API, Django] 네이버 검색 API 사용 (0) | 2023.03.15 |
| [API, Django] TMDB API 사용, 콘텐츠 정보 불러오기 (4) (0) | 2023.03.15 |
| [API, Django] TMDB API 사용, 콘텐츠 정보 불러오기 (3) (0) | 2023.03.15 |