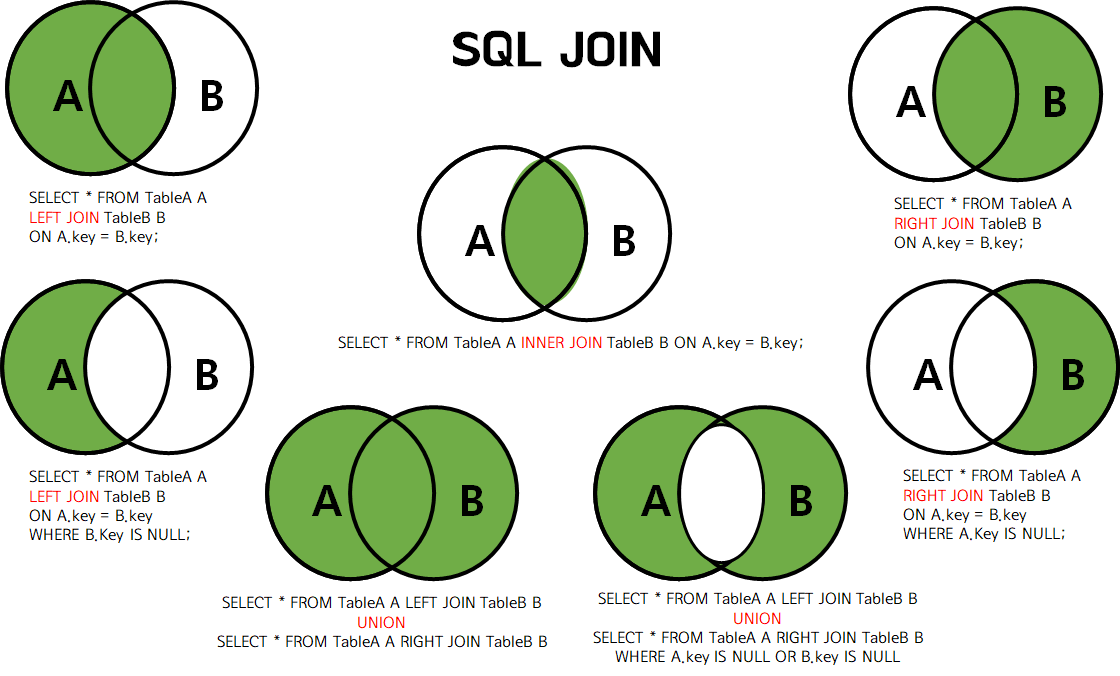
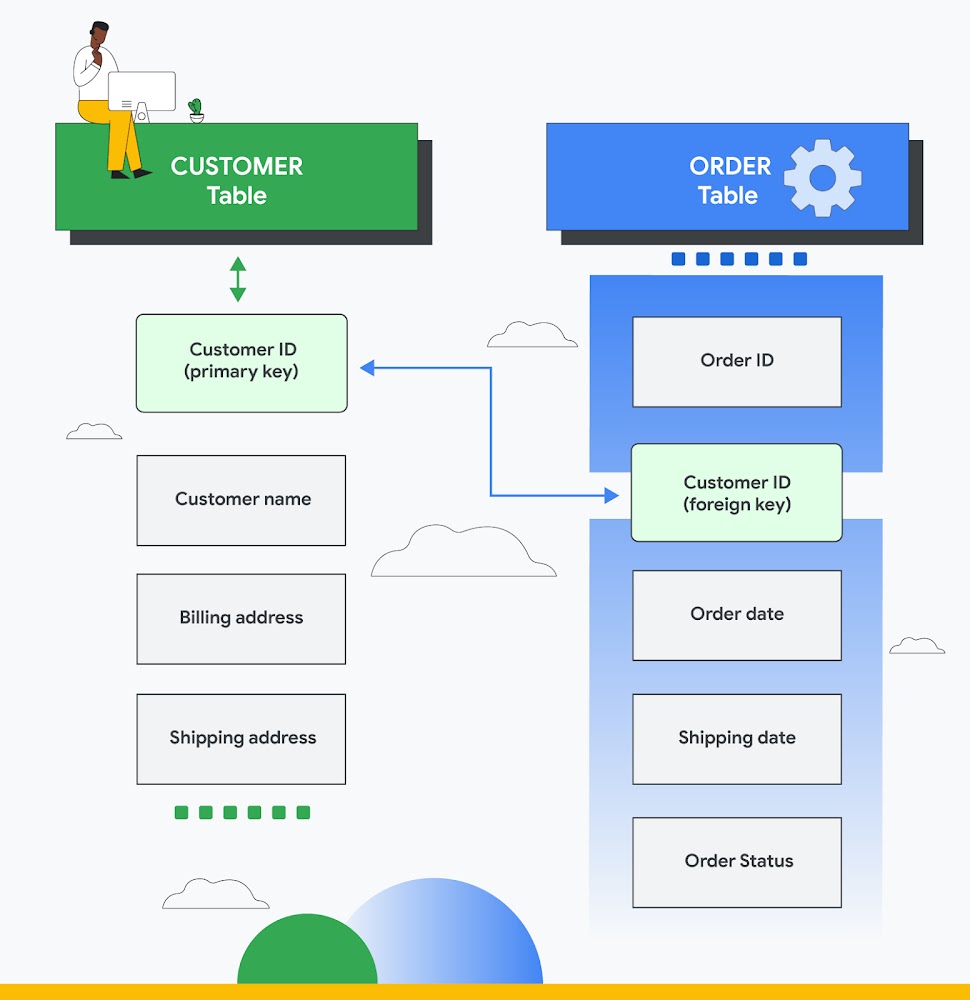
1. Join(조인) 이란?- 둘 이상의 테이블을 연결하여 하나의 결과를 만들어 내는 것 1) 전제조건- 연결하고자 하는 테이블들이 적어도 하나의 컬럼을 공유하고 있어야 함 (두 테이블의 조인을 위해서는 기본키(PK)와 외래키(FK) 관계로 맺어져야 함) 2. Join의 종류 1) INNER JOIN교집합기준 테이블과 JOIN 테이블의 중복된 값두 테이블에 모두 지정한 열의 데이터가 있어야 함 # 문법SELECT *FROM TABLE_A A INNER JOIN TABLE_B B ON A.KEY = B.KEYWHERE 조건 # JOIN 완료 후 그 다음 조건 따짐# 단순 문법 - FROM 절에 , 쓰면 INNER JOIN SELECT *FROM TABLE_A A, TABLE_B BWHERE A.KEY ..